本文是我用webpack进行项目构建的实践心得,场景是这样的,项目是大型类cms型,技术选型是vue,只支持chrome,有诸多子功能模块,全部打包在一起的话会有好几MB,所以最佳方式是进行多入口打包。文章包含我探索的过程以及webpack在使用中的一些技巧,希望能给大家带来参考价值。
首先,项目打包策略遵循以下几点原则:
- 选择合适的打包粒度,生成的单文件大小不要超过500KB
- 充分利用浏览器的并发请求,同时保证并发数不超过6
- 尽可能让浏览器命中304,频繁改动的业务代码不要与公共代码打包
- 避免加载太多用不到的代码,层级较深的页面进行异步加载
基于以上原则,我选择的打包策略如下:
- 第三方库如vue、jquery、bootstrap打包为一个文件
- 公共组件如弹窗、菜单等打包为一个文件
- 工具类、项目通用基类打包为一个文件
- 各个功能模块打包出自己的入口文件
- 各功能模块作用一个SPA,子页面进行异步加载
各入口文件的打包
由于项目不适宜整体作为一个SPA,所以各子功能都有一个自己的入口文件,我的源码目录结构如下:
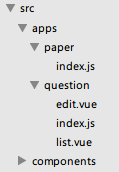
apps目录下放置各个子功能,如question和paper,下面是各自的子页面。components目录放置公共组件,这个后面再说。
由于功能模块是随时会增加的,我不能在webpack的entry中写死这些入口文件,所以用了一个叫做glob的模块,它能够用通配符来取到所有的文件,就像我们用gulp那样。动态获取子功能入口文件的代码如下:
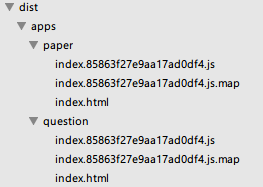
/*** 动态查找所有入口文件*/var files = glob.sync('./public/src/apps/*/index.js');var newEntries = {};files.forEach(function(f){ var name = /.*\/(apps\/.*?\/index)\.js/.exec(f)[1];//得到apps/question/index这样的文件名 newEntries[name] = f;});config.entry = Object.assign({}, config.entry, newEntries); webpack打包后的目录是很乱的,如果你入口文件的名字取为question,那么会在dist目录下直接生成一个question.xxxxx.js的文件。但是如果把名字取为apps/question/index这样的,则会生成对应的目录结构。我是比较喜欢构建后的目录也有清晰的结构的,可能是习惯gulp的后遗症吧。这样也便于我们在前端路由中进行统一操作。也是一个小技巧吧,我生成的各入口文件的目录如下:
第三方库的打包
项目中用到了一些第三方库,如vue、vue-router、jquery、boostrap等。这些库我们基本上是不会改动源代码的,并且项目初期就基本确定了,不会再添加。所以把它们打包在一起。当然这个也是要考虑大小不超过500KB的,如果是用到了像ueditor这样的大型工具库,还是要单独打包的。
配置文件的写法是很简单的,在entry中配一个名为vendor的就好,比如:
entry: { vendor: ['vue', 'vue-router', './public/vendor/jquery/jquery']}, 不管是用npm安装的还是自己放在项目目录中的库都是可以的,只要路径写对就行。
为了把第三方库拆分出来(用<script>标签单独加载),我们还需要用webpack的CommonsChunkPlugin插件来把它提取一下,这样他就不会与业务代码打包到一起了。代码:
new webpack.optimize.CommonsChunkPlugin('vendor'); 公共组件的打包
这部分代码的处理我是纠结了好久的,因为webpack的打包思想是以模块的依赖树为标准来进行分析的,如果a模块使用了loading组件,那么loading组件就会被打包进a模块,除非我们在代码中用require.ensure或者AMD式的require加回调,显式声明该组件异步加载,这样loading组件会被单独打包成一个chunk文件。
以上两者都不是我想要的,理由参见文章开头的打包原则,把所有公共组件打包在一起是一个自然合理的选择,但这又与webpack的精神相悖。
一开始我想到了一招曲线救国,就是在components目录下建一个main.js文件,该文件引用所有的组件,这样打包main.js的时候所有组件都会被打包进来,main.js的代码如下:
import loading from './loading.vue';import topnav from './topnav.vue';import centernav from './centernav.vue';export {loading, topnav, centernav} 有点像sass的main文件的感觉。使用的时候这样写:
let components = require('./components/main');export default { components: { loading: (resolve) =>{ require(['./components/main'],function(components){ resolve(components.loading); }) } }} 缺点是也得写成异步加载的,否则main.js还是会被打包进业务代码。
不过后来我又一想,既然vendor可以,为什么组件不可以用同样的方式处理呢?于是乎找到了最佳方法。 同样先用glob动态找到所有的components,然后写进entry,最后再用CommonsChunkPlugin插件剥离出来。代码如下:
/*动态查找所有components*/var comps = glob.sync('./public/src/components/*.vue');var compsEntry = {components: comps};config.entry = Object.assign({}, config.entry, compsEntry); 要注意CommonsChunkPlugin是不可以new多个的,要剥离多个需要传数组进去,写法如下:
new webpack.optimize.CommonsChunkPlugin({ names: ['vendor', 'components']}) 如此一来,components就和vendor一样可以用<script>标签引入页面了,使用的时候就可以随便引入了,不会再被重复打包进业务代码。如:
import loading from './components/loading';import topnav from './components/topnav';
把这些文件塞进入口页面
之前说过我们的子功能模块有各自的页面,所以我们需要把这些文件都给引入进这些页面,webpack的HtmlWebpackPlugin可以做这件事情,我们在动态查找入口文件的时候顺便把它做了就行了,代码如下:
/** * 动态查找所有入口文件 */var files = glob.sync('./public/src/apps/*/index.js');var newEntries = {};files.forEach(function(f){ var name = /.*\/(apps\/.*?\/index)\.js/.exec(f)[1]; //得到apps/question/index 这样的文件名 newEntries[name] = f; var plug = new HtmlWebpackPlugin({ filename: path.resolve(__dirname, '../public/dist/'+ name +'.html'), chunks: ['vendor', name, 'components'], template: path.resolve(__dirname, '../public/src/index.html'), inject: true }); config.plugins.push(plug);}); 子页面的异步载入
每个功能模块是作为一个SPA应用来处理的,这就意味着我们会根据前端路由来动态加载相应子页面,使用官方的vue-router是很容易实现的,比如我们在question/index.js中可以如下写:
router.map({ '/list': { component: (resolve) => { require(['./list.vue'], resolve); } }, '/edit': { component: (resolve) => { require(['./edit.vue'], resolve); } }}); 在webpack的配置文件中就无需再写什么了,它会自动打包出对应的chunk文件,此时我的dist目录就长这样了:
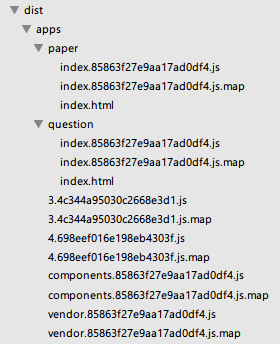
有一点让我疑惑的是,异步加载的chunk文件貌似无法输出文件名称,尽管我在output参数中这么配置:chunkFilename: '[name].[chunkhash].js',[name]那里输出的还是id,可能和webpack处理异步chunk的机制有关吧,猜测的。不过也无所谓的,反正能够正确加载,就是名字难看点。
--------更新于2016.10.11-------
为异步chunk命名的方法我找到了,需要两步。首先output中还是应该这么配置:chunkFilename: '[name].[chunkhash].js'。然后,利用require.ensure的第三个参数,可以为chunk指定名字。上面的代码修改为如下:
router.map({ '/list': { component: (resolve) => { // require(['./list.vue'], resolve); require.ensure([], function(){ resolve(require('./list.vue')); }, 'list'); } }, '/edit': { component: (resolve) => { //require(['./edit.vue'], resolve); require.ensure([], function(){ resolve(require('./edit.vue')); }, 'edit'); } }}); 这样list和edit这两个组件生成的chunk就有名字了,如下:
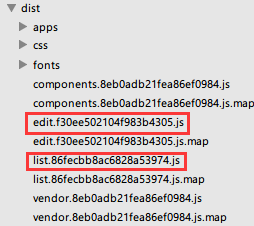
我个人还是偏好生成的chunk能带上名字,这样可读性好一些,便于调试和尽快发现错误。
以上就是一个大概的架子了,由于我也是刚刚开始探索webpack(之前gulp党),一边 实践一边分享吧,还有很多细节的东西没法细讲,我在本系列文章中慢慢道来吧。